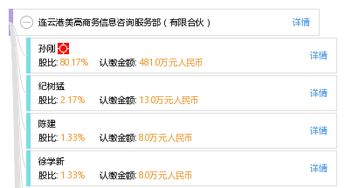
群核科技(酷家樂)完成新一輪增資的消息引發了行業廣泛關注。這不僅為其注入了新的發展動能,也標志著這家以云設計軟件起家的科技公司,其商業版圖正邁向更綜合、更深度的戰略布局。信息咨詢服務,作為其業務生態中日益重要的一環,正成為連接技術、數據與行業決策的關鍵樞紐,助力群核科技構建更完整的產業賦能體系。
一、增資背后的戰略意圖:從工具到生態的深化
群核科技去年的增資,遠非簡單的資本補充。其核心意圖在于深化其從“設計工具提供商”向“大家居產業數字化解決方案服務商”的戰略轉型。
- 技術研發與產品迭代:資金將持續投入底層核心技術,如云渲染引擎、AI智能設計、BIM(建筑信息模型)等,鞏固其在可視化設計領域的領先地位。這是其所有業務延伸的基石。
- 生態平臺構建:增資將用于強化其平臺連接能力,吸引更多產業鏈伙伴(如建材商、裝修公司、設計師、開發商)入駐,形成從設計、營銷、生產到施工的數據閉環生態。
- 新業務線拓展:信息咨詢服務正是其生態價值變現和業務縱深的重要方向之一。基于海量的行業設計數據、用戶行為數據及供應鏈數據,群核科技有能力提供遠超傳統工具的決策支持。
二、商業版圖全景盤點:四大支柱協同發力
經過多年發展,群核科技已構建起一個以云設計軟件為核心,輻射多場景應用的商業矩陣。
- 核心SaaS產品矩陣:以“酷家樂”為主品牌,涵蓋家居、公裝、房產、建筑等領域的設計工具,服務超過千萬設計師與超25000家品牌企業。這是其流量入口和數據之源。
- 數字化營銷解決方案:為家居品牌提供從方案設計、虛擬展廳、在線引流到客戶管理的全鏈路營銷工具,幫助客戶實現營銷數字化轉型。
- 供應鏈與產業互聯:通過“到師傅”等平臺連接設計與落地服務,并嘗試打通設計與后端生產制造(如全屋定制),推動產業鏈效率提升。
- 信息與數據咨詢服務:這是基于其平臺積淀的獨特優勢生長出的高階服務板塊。它不再僅僅是提供軟件,而是輸出“知識”、“洞察”和“策略”。
三、信息咨詢服務:數據價值的深度挖掘
信息咨詢服務是群核科技商業版圖中極具潛力的增長極。它主要依托其龐大的數據庫和行業洞察能力,為企業客戶提供多維度的決策支持。
- 市場趨勢與用戶洞察報告:基于平臺產生的億級設計方案數據,分析全國乃至特定區域的戶型偏好、風格流行趨勢、材料選用熱點、空間功能需求變化等,為企業的產品研發、市場定位提供精準數據參考。
- 競爭分析與品牌策略咨詢:幫助客戶洞悉競爭對手的市場動態、產品策略和營銷方式,并結合行業大數據,為客戶制定差異化的品牌與競爭策略。
- 數字化升級路徑規劃:針對傳統家居建材企業,提供從營銷、設計到生產制造全流程的數字化診斷與轉型路徑規劃咨詢服務,幫助其高效接入數字化生態。
- 專項研究項目:針對行業熱點(如存量房改造、適老化家居、智能家居集成等)或客戶特定需求,開展定制化的深度研究項目,輸出具有前瞻性和實操性的行業白皮書或解決方案。
四、未來展望:以信息智能驅動產業革命
完成增資后的群核科技,其信息咨詢服務板塊有望迎來更系統化的發展。該服務可能呈現以下趨勢:
- 產品化與標準化:將部分咨詢服務成果固化為可訂閱的數據產品或標準分析工具,降低使用門檻,服務更廣泛的中小客戶。
- AI賦能深度分析:利用人工智能技術,對設計數據、用戶評論、社交媒體輿情等進行更深度的情感分析和需求預測,使洞察更具前瞻性和動態性。
- 與業務場景深度集成:咨詢服務產生的洞察將更直接地反饋并融入其SaaS產品和營銷解決方案中,形成“數據洞察-工具優化-策略落地”的增強循環,為客戶創造閉環價值。
群核科技的增資是其商業旅程中的一個重要里程碑。通過盤點其商業版圖,特別是信息咨詢服務這一新興板塊,我們可以看到,其戰略核心正從“賦能設計”升級為“賦能決策”。通過將沉淀的數據資源轉化為可行動的行業智慧,群核科技不僅鞏固了其技術護城河,更在大家居產業數字化浪潮中,扮演著越來越關鍵的“智庫”與“連接器”角色。其未來的發展,值得持續關注。